Machine learning derivatives
Published on 06/03/2021
Derivatives are frequently used in machine learning because it allows us to efficiently train a neural network. An analogy would be finding which direction you should take to reach the highest mountain but with the restriction of only being able to see one meter away. In this article, we will first recall the rules of derivatives and partial derivatives. Then we will feature a few derivatives of functions that are commonly used in machine learning.
The derivatives rules
The basics
Let’s start by the derivatives of common functions. In the following :
-
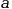 is a constant
is a constant -
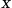 is the variable by which we derive the functions
is the variable by which we derive the functions -
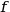 and
and 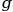 are functions
are functions -
Also note that
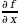 is equivalent to
is equivalent to 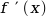
| Function |
Derivative |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Here are a few derivative rules that we will use in the following sections.
| Rule | Function | Derivative |
|---|---|---|
Multiplication by a constant |
|
|
Sum |
|
|
Difference |
|
|
Product |
|
|
Quotient |
|
|
Reciprocal (from quotient) |
|
|
The chain rule
![]() means
means ![]() . We can also rewrite it using Leibniz’s notation :
. We can also rewrite it using Leibniz’s notation :
Which literally says : the derivative ![]() by
by ![]() is the derivative
is the derivative ![]() by (
by (![]() )
) ![]() multiplied by the derivative
multiplied by the derivative ![]() .
.
Partial derivatives and gradient
Let’s define a function :
How can we calculate the derivative of this function ?
When a functions takes more than one variable as an argument, we can calculate the derivative of the function with respect to each variable. When we do that, the variables are treated as constants :
We define the gradient of a function as the vector of all its parial derivatives, in this case the gradient ![]() of the function
of the function ![]() is :
is :
More generally, for a function ![]() that takes a vector
that takes a vector ![]() as an argument, its gradient is defined by
as an argument, its gradient is defined by ![]() .
.
The sigmoid
A sigmoid is a "S"-shaped curve. The one we use is called the logistic function and it is defined like this :
Here is a graph of what it looks like, along with its derivative :
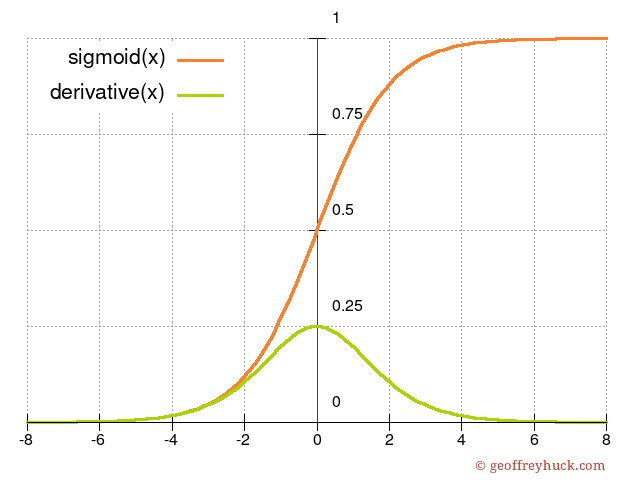
Let’s compute its derivative :
After using the reciprocal rule. Now we first calculate the right part using again the reciprocal rule :
So we have :
Now we use a little trick on the right part, adding ![]() on the top :
on the top :
You remember that ![]() ? So we can write :
? So we can write :
The squared error function
The squared error function is defined by :
We usually use this function for a batch of examples, which gives us the following formula where the variables are vectors :
And sometimes, the output of an example is itself a vector (think about an artificial neural network with multiple output units), we then have the following where the variables are matrices :
The square of a difference is always positive, therefore the more difference there is between the true output and the predicted output, the bigger the result. The ![]() term is only used because it makes the derivative more convenient, as you we see.
term is only used because it makes the derivative more convenient, as you we see.
Now what we want is the partial derivative with respect to :
-
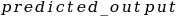 for the first variant of the function;
for the first variant of the function; -
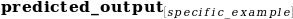 for the second variant;
for the second variant; -
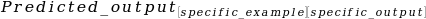 for the third variant.
for the third variant.
When we calculate a partial derivative, all the other variables are treated as a constant. This means that in the case of the third variant, each ![]() that are not of indexes
that are not of indexes ![]() will have a derivative equal to
will have a derivative equal to ![]() .
.
Therefore we can get rid of the sums for the calculations of the partial derivatives of ![]() , which means we only have to consider the first variant.
, which means we only have to consider the first variant.
We will name the specific variable we derive the function for ![]() , and the corresponding true output
, and the corresponding true output ![]() .
.
Now let’s start :
After using the chain rule. Now let’s simplify the result :
Or for the second variant :
And for the third variant :